[ad_1]
At the moment, we’re happy to current a visitor contribution by Laurent Ferrara (Professor of Economics at Skema Enterprise College, Paris and Director of the Worldwide Institute of Forecasters).
The latest sequence of financial, monetary and pandemic crises across the globe has significantly shortened the horizon of predictions for macroeconomic forecasters. On the coronary heart of the Covid-19 disaster, the horizon of curiosity was relatively the top of the week than two years-ahead. This led practitioners to deal with new sorts of high-frequency and different datasets, elevating thus new challenges for econometricians (unstructured information, very giant datasets, blended frequencies, excessive volatility, brief samples …).
Numerous sources of other information have been used within the latest literature, comparable to for instance net scraped information, scanner information or satellite tv for pc information. Typically, these datasets are extraordinarily giant and could be thought-about as huge information. One of many important sources of other information are Google search information, and seminal papers on the usage of such information for forecasting are those by Hal Varian and co-authors (see for instance right here). Within the space of nowcasting/forecasting, the literature tends to indicate proof of some forecasting energy for Google information, not less than for some particular macroeconomic variables comparable to unemployment fee (D’amuri and Marcucci, 2017) en employment (Borup and Montes Schütte, 2020), constructing permits (Coble and Pincheira, 2017) or automobile gross sales (Nymand and Pantelidis, 2018). Nonetheless, when accurately in contrast with different sources of data, the jury continues to be out on the achieve that economists can get from utilizing Google information for forecasting and nowcasting. A aspect query, extremely debated on Econbrowser is concerning the replicability of these information by practitioners (see right here for a dialogue between Hal Varian and Simon van Norden).
In a latest paper, revealed with Anna Simoni within the Journal of Enterprise and Financial Statistics (see right here for a mimeo), we ask ourselves whether or not Google information are nonetheless helpful in nowcasting quarterly GDP progress when controlling for official variables, comparable to opinion surveys or manufacturing manufacturing, typically utilized by forecasters. And if that’s the case, when precisely are these different information including a achieve in nowcasting accuracy. Nowcasting GDP progress is extraordinarily helpful for policy-makers to evaluate macroeconomic situations in real-time. The idea of macroeconomic nowcasting has been popularized by Giannone et al. [2008] and differs from normal forecasting approaches within the sense it goals at evaluating present macroeconomic situations on a high-frequency foundation. The thought is to offer policy-makers with a real-time analysis of the state of the economic system forward of the discharge of official Quarterly Nationwide Accounts, that all the time come out with a delay. See for instance right here for the U.S. economic system and right here for a latest put up on Econbrowser.
As a result of Google search information are of excessive dimension, within the sense that the variety of variable is giant in comparison with the time collection dimension, there’s a value to pay for utilizing them: first, we have to cut back their dimensionality from ultra-high to excessive by utilizing a screening process and, second, we have to use a regularized estimator to cope with the pre-selected variables. Regularization methods are a method to account for a lot of variables, probably correlated, right into a linear regression (see for instance the Ridge estimation). On this respect, we put ahead a brand new method combining variable pre-selection and Ridge regularization enabling to account for a big database. Within the paper, we offer some theoretical outcomes as regards the great asymptotic properties of this estimation technique, that we confer with as Ridge after Mannequin Choice.
Along with these theoretical outcomes, we get a bunch of empirical outcomes that may very well be fascinating to share with individuals taken with utilizing excessive dimensional different information for macroeconomic nowcasting. Our goal is to nowcast GDP progress each week of the quarter, for the U.S., euro space and Germany over 3 sorts of financial durations: (i) a relaxed interval (2014-16), (ii) a interval with a sudden downward shift in GDP progress (2017-18, associated to commerce warfare between U.S and China/Europe) and (iii) a recession interval with giant unfavorable progress charges (2008-09, pushed by the International Monetary Disaster). On this respect we use classical macro information (surveys and manufacturing), in addition to different information stemming from Google (Google Search Knowledge, already grouped into classes and sub-categories). We evaluate varied approaches primarily based on their nowcasting potential, as measured by the Root Imply Squared Forecasting Error (RMSFE). 4 salient details emerge from our empirical evaluation.
First, we evaluate an ordinary regression (with Ridge regularization) with a regression after preselection (our Ridge after Mannequin Choice method). Determine 1 exhibits the outcomes for the euro space throughout a relaxed interval (2014-16). We clearly see the achieve by way of nowcasting accuracy of pre-selecting information earlier than getting into into the mannequin. The thought is that having too many variables provides an excessive amount of noise. That is particularly the case with Google Search Knowledge, as a few of them aren’t straight associated to financial exercise. This end result confirms earlier outcomes in opposition to the background of dynamic issue fashions (see Bai and Ng, 2008 or Barhoumi et al., 2009).
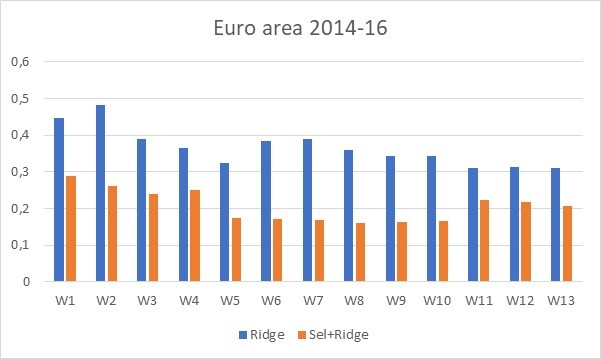
Determine 1: RMSFEs for the euro space throughout a relaxed interval (2014-16) stemming from an ordinary regression with Ridge regularization (blue bars) and from the Ridge after Mannequin Choice method (orange bars). Evolution of RMSFEs inside the 13 weeks of the present quarter. Supply: Ferrara and Simoni (2023)
Second, we level out the usefulness of Google search information in nowcasting GDP progress fee for the primary 4 weeks of the quarter, that’s when there isn’t any official details about the state of the present quarter. In Determine 1, we see that firstly of the quarter (from week 1 to week 4), Google information certainly present an correct image of the GDP progress fee within the sense that RMSFEs are moderately low (between 0.2% and 0.3%), barely greater than these on the finish of the quarter when all the data is accessible (about 0.2%).
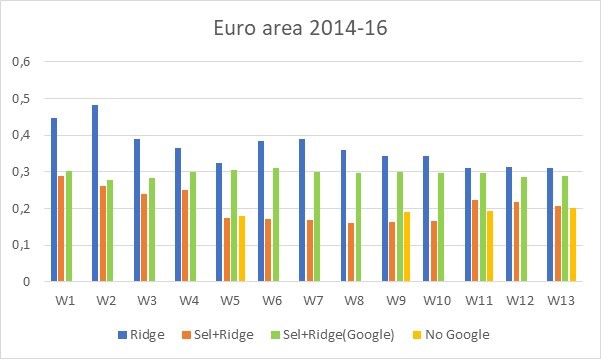
Determine 2: RMSFEs for the euro space throughout a relaxed interval (2014-16) stemming from an ordinary regression with Ridge regularization (blue bars), from the Ridge after Mannequin Choice method (orange bars), from the Ridge after Mannequin Choice method utilizing solely Google information (inexperienced bars) and from a primary regression mannequin with none Google information (yellow bars) . Evolution of RMSFEs inside the 13 weeks of the present quarter Supply: Ferrara and Simoni (2023)
Third, as quickly as official information turn into obtainable, that’s ranging from week 5 with the discharge of the primary opinion survey of the quarter (within the euro space case), then the relative nowcasting energy of Google information quickly vanishes. We see in Determine 2, that for the week 5, the RMSFE with all information (orange bar) is equal to the one with none Google information (the yellow bar), that’s. with solely macro info contained within the first survey of the quarter. We additionally word that RMSFEs stemming from the Ridge after Mannequin Choice method utilizing solely Google information (inexperienced bars) don’t present any decline additional time, suggesting that the achieve seen in orange bars ranging from week 5 is coming from the combination of macro variables.
Fourth, recession durations current a selected sample, because the mannequin with none pre-selection and with solely Google information as info set gives the bottom RMSFEs (inexperienced bars in Determine 3). This sample can be typically seen for German and U.S. information. This end result have to be additional understood by further analysis, but it surely may be associated to the well-known greater uncertainty that we observe throughout recessions, that means that extra information have to be used to account for it. In any case, this may be seen as a justification of the usage of different information throughout crises.
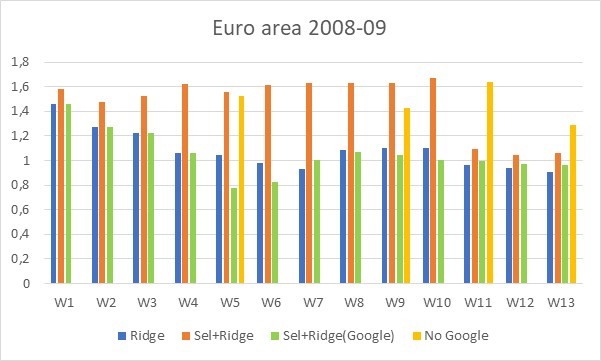
Determine 3: RMSFEs for the euro space throughout a recession interval (2008-09) stemming from an ordinary regression with Ridge regularization (blue bars), from the Ridge after Mannequin Choice method (orange bars), from the Ridge after Mannequin Choice method utilizing solely Google information (inexperienced bars) and from a primary regression mannequin with none Google information (yellow bars) . Evolution of RMSFEs inside the 13 weeks of the present quarter Supply: Ferrara and Simoni (2023)
Numerous robustness checks affirm that these empirical outcomes nonetheless maintain for all of the nations/areas in our evaluation and are nonetheless legitimate once we enhance the macroeconomic info set by contemplating 22 standard variables (gross sales, exports, employment, …). Final a true-real evaluation for the euro space with vintages of information affirm the rating of the assorted approaches. Total, all these outcomes level out that Google information could be very helpful for GDP progress nowcasting throughout enlargement phases when info is missing, after a pre-selection step. Nonetheless, as quickly as official macroeconomic info arrives, the marginal achieve from Google information tends to quickly vanish. Throughout recession phases, it appears that evidently forecasters want the most important obtainable info set to evaluate what’s happening within the financial exercise.
This put up written by Laurent Ferrara.
[ad_2]